


Depending where your company stands in your data journey, you may or may not be familiar with reverse-ETL. While many organizations have managed to centralize their data in a data warehouse, figuring out what to then do with this data is a common challenge. Beyond standard visualizations and reporting, it can feel like something’s missing from your data operations — like there’s a secret to becoming data-driven that needs to be unlocked.
Wonder no more, the secret to data-driven business is reverse-ETL.
In recent years, Snowflake, Google BigQuery, Amazon Redshift and other data warehouses have rapidly become the central nervous system of businesses. And bringing all of your insights into one secure, organized location is essential, but too often, this is where data efforts end. Reverse-ETL is the missing piece of data activation, and there are modern tools to make this a reality at your company.
Keep reading to learn how reverse-ETL brings your data out of the warehouse and into your daily operations. Plus, we’ll go over some examples of reverse-ETL in action, and how to select the right reverse-ETL tool for your needs.
Defining reverse-ETL
Simply put, reverse-ETL is the connectors that extract data from your data warehouse and bring it into the tools, apps, and other destinations that your teams use in their every day. To make that a little clearer, let’s take a step back and go over some basics.
What is ETL, or ELT?
Before launching into what reverse-ETL is, it’s important to understand what ETL is. ETL stands for ‘Extract, Transform, Load’ and is also known as ELT because usually in a modern data setup, it’s done in the order of ‘Extract, Load, Transform’.
ELT is the process of taking data from a system of record, usually an app like Hubspot or a database like PostgreSQL, and copying it into a data warehouse. This is done through pipelines that are usually built by data engineers to extract the right data from various sources.
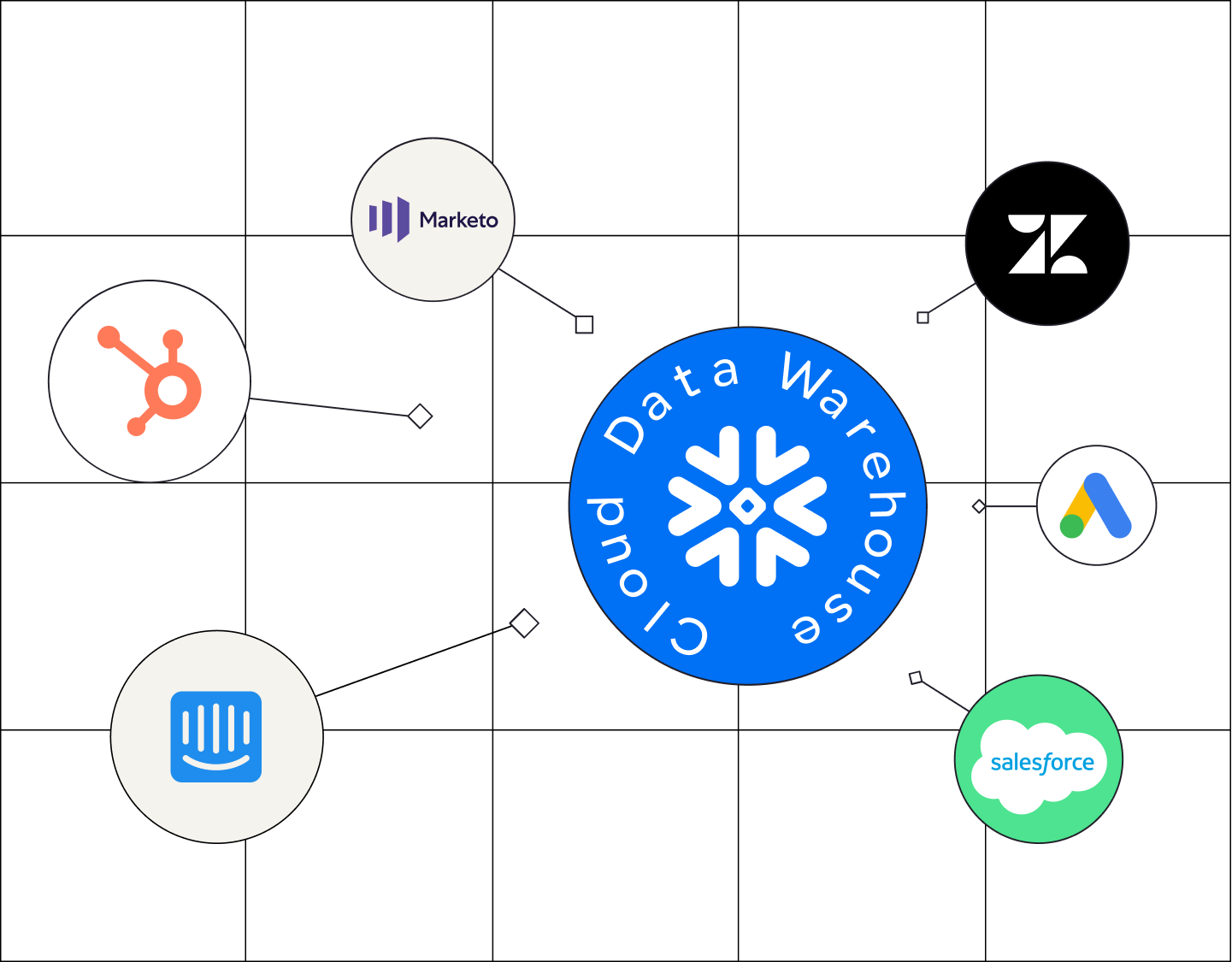
What is a Modern Data Stack?
It's easier to understand what ETL means if you’re familiar with the concept of a modern data stack. A modern data stack is the set of tools that manage your data, and usually has 6 components: sourcing, ingestion, storage, modeling, visualization and activation. It’s how data goes from dispersed, unstructured, and unusable to centralized, organized, and actionable.
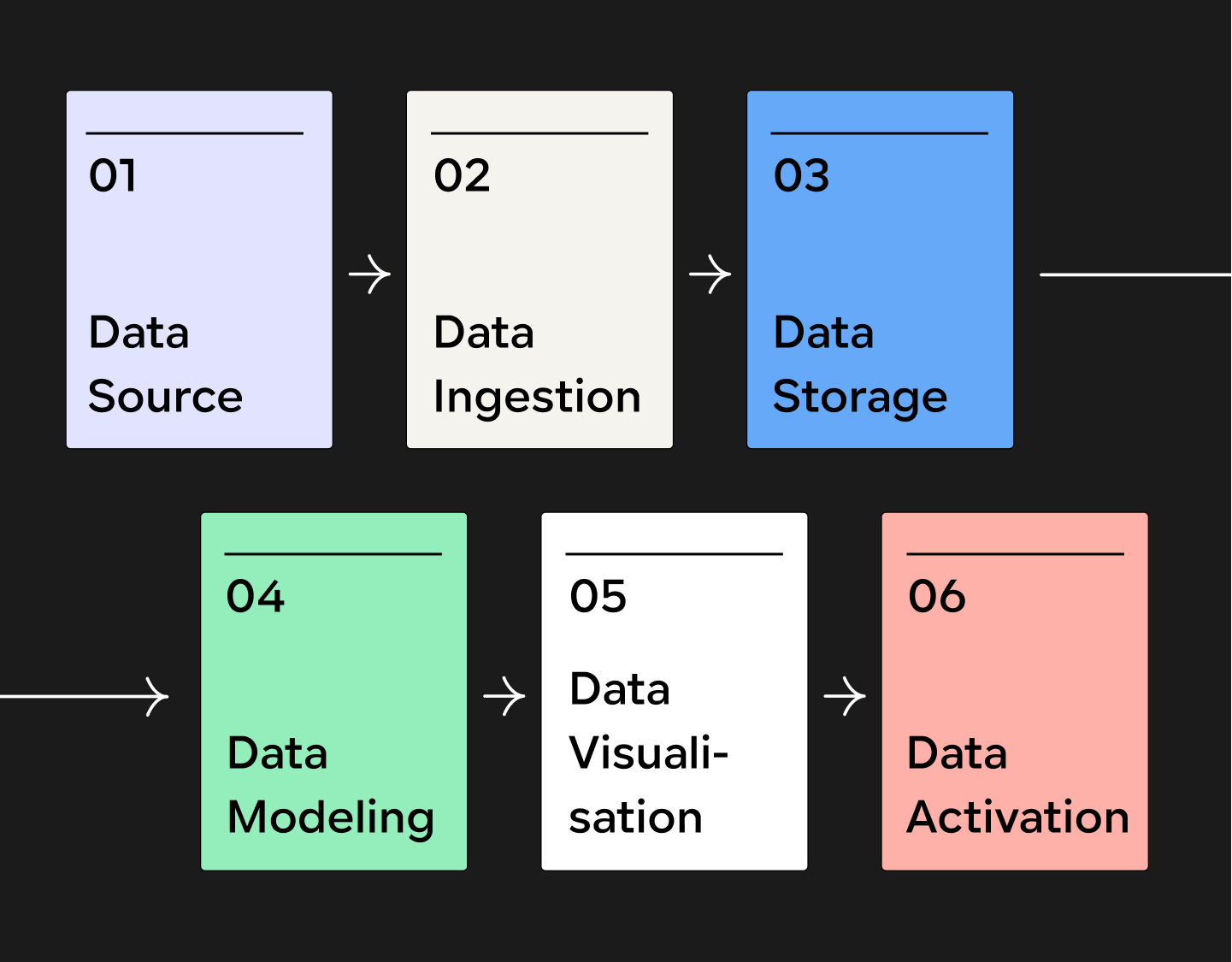
ELT pipelines are the second piece of the data stack, ingestion. Your ELT connectors are what take your data from the source to the data warehouse, and transform it into a usable state.
What is reverse-ETL?
With all of that context, reverse-ETL is essentially the opposite of ETL. It's the process of moving your data back out of your data warehouse and into the tools and apps your teams use every day. But this is happening after the data has been centralized, cleaned, and structured to be usable — and this is why reverse-ETL is the key to data activation.
With reverse-ETL, you can sync your core business metrics like CAC, LTV & Health Score to all your tools, bringing data into every team’s daily operations. Reverse-ETL is arguably the most important step in a modern data stack, and essential to achieving data-driven success.
What are the use cases for reverse-ETL?
There are many benefits of reverse-ETL, notably the fact that teams no longer have to go seek out the data they need to make decisions and build strategies. Instead, the data is already there in the software and tools where they need it. Plus, creating and maintaining KPI alignment across teams is simplified, on top of making sure everyone has the same business definitions of core metrics.
But more concretely, what does reverse-ETL look like in action? Let’s dig into 3 main use cases of reverse-ETL and real-life examples of what this helps companies accomplish.
1. Data automation for streamlined workflows
With reverse-ETL, you’re able to use data automation to build more efficient, streamlined workflows. In essence, reverse-ETL feeds key data points and metrics into operational systems at a predefined frequency. In turn, this data can automate a variety of workflows directly within the operational system it was pushed to.
For example: Say your company’s CRM is Hubspot, and your sales and CS teams use it in their day-to-day. One of the main responsibilities of your sales team is to monitor freemium accounts and convert them to paying customers. To do so, your account managers need to know how far their accounts are in the sales funnel, which means that they often have to jump between the CRM and BI tools.
With reverse-ETL, you can take the product data in your warehouse, push it to Hubspot, and create an alert where the right account managers will be notified when a freemium account has reached a specific threshold in the sales funnel. No need for people to continually jump from one platform to another, and no missed or delayed opportunities — just data-driven efficiency in the flow of work.
2. Breaking down data silos across teams
Data silos are an all too familiar blocker to high performance and company alignment. Having important customer data living in different tools, with no single source or truth, means that teams are working off of different information and perspectives — or worse, with no data at all. How can commercial teams effectively collaborate to reduce your customer acquisition cost if they can’t agree on what it is to begin with?
This is part of the reason why data warehouses are a necessity for today’s businesses. And this is great, because cloud data warehouses are a safe, reliable and affordable tool to centralize and aggregate customer data from all of your apps.nBut while many companies invest in a data warehouse in the hopes of eliminating data silos, the data warehouse can, ironically, quickly become a data silo itself.
Without reverse-ETL, your core business metrics only live in your data warehouse, making them only a fraction as useful as they could be. But with reverse-ETL pipelines in place, data is brought out of the warehouse and into your operations. Not only does everyone have access to your company data, the same data is showing up in all the various SaaS apps and tools every team is using.
For example: A marketer using Customer.io, a support agent using Zendesk and an Account Manager using Salesforce all see the same accurate and up-to-date health score metrics for all their customers in their respective tools.
3. More efficient, impactful work and better performance
When teams need to spend a significant amount of time and energy manually working with or looking for data, they’re blocked from doing innovative, high-impact work. With a reverse-ETL tool, they’re freed up to pursue the work they were hired to do. Here are a few examples of how teams benefit from reverse-ETL:
- Data teams no longer have to spend the bulk of their time building and managing data pipelines manually. They can instead focus on doing more exciting and engaging work like building data models for the entire organization.
- Sales teams no longer have to spend time looking through 5-10 tabs to find the right information about their customers. It all lives inside their CRM.
- Support teams have their incoming tickets automatically sorted by order of priority through reverse-ETL, based on the health score metric.
- Marketing teams can create email marketing campaigns that are hyper-targeted, using metrics like CAC, health score or MRR to segment users.
What to look for in a reverse-ETL tool
Although reverse-ETL is needed to become truly data-driven in today's business world, not all reverse-ETL tools are created equal. Here are some key factors to look for when choosing a reverse-ETL tool to ensure you get the best option for your business.
Reliable syncing is a must
Syncing is in many ways the most critical function that a reverse-ETL tool performs. It's what keeps all of your data aligned in real-time. If it isn't functioning, then your teams and systems could be working with faulty data. Make sure that your reverse-ETL tool prioritizes syncing.
The latest in security technology and regulations
As reverse-ETL tools deal with data, security and privacy are a must. Not only are customers and businesses becoming more literate when it comes to digital security, but so are regulators. This means that businesses not only need to keep their data secure for themselves and their customers, but also to avoid fees, penalties, and worse.
Integrations with the tools you use
You’ll also need to consider the tools that a particular reverse-ETL tool can integrate with. This is especially true if you're already using various apps, services, and systems across your teams. Most reverse-ETL solutions will list the apps and services that they integrate with. Create your own list of the services where you’d want to use reverse-ETL, and check that list against the available integrations in a potential reverse-ETL tool.
Leverage data with Weld's cutting-edge reverse-ETL
Built by engineers, Weld’s reverse-ETL connectors help companies of various sizes and industries bring data into their daily operations. Plus, Weld is a complete solution that sits on top of your data warehouse to handle all the functions of a modern data stack. If you’re looking for a tool that can source, extract, transform, and activate your company data, why not give Weld a try or chat with one of our experts to see what Weld can do for your teams.
Continue reading
New Feature - AI Context
Our AI assistant, Ed, now lets you include contexts for your prompt, beyond all the useful features it already had!


How to set up your Shopify metrics in Weld
Learn how to set up your Shopify metrics in Weld and get actionable insights from your data.


New Connector Alert - Google My Business Profile
Looking to optimize your Google My Business Profile reporting? With our new ETL connector, you can effortlessly integrate your Google My Business Profile data with all your other data sources. Create a comprehensive view of your business metrics, enhance your analytics, and make more informed decisions with ease!




